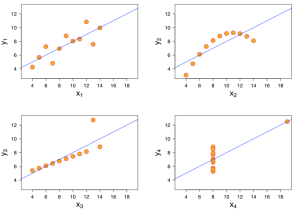
Читая эту статью наткнулся на интересное замечание. В 1973 году английский математик Francis Anscombe привел пример того как немедленный статистический анализ данных(без предварительной визуализации) может привести к неправильным выводам о свойствах этих данных. На следующей картинке проиллюстрированы четыре набора данных с очень близкими значениями статистик:
а именно:
Среднее значение переменной x = 9.0
Дисперсия переменной x = 11,0
Среднее значение переменной y = 7,50 (с точностью до двух значащих цифр после запятой)
Дисперсия переменной y = 4,122 или 4,127 (с точностью до трех значащих цифр после запятой)
Корреляция между переменными x и y = 0,816 (с точностью до трех значащих цифр после запятой)
Уравнение регрессии: y = 3,00 + 0.500 * x (с точностью до двух и трех значащих цифр после запятой соответственно)
Сами данные можно найти по ссылке : Wiki
PS: Как часто бывает, данные/определения в английской и русской версиях отличаются)